
복잡한 분기처리, 의사결정 테이블 형태로 표현하기
개요
개발을 진행하다 보면 다양한 케이스에 따른 분기 처리가 빈번하게 발생합니다.
대부분의 경우 if문이나 switch문을 사용해 해결하곤 하지만, 조건이 복잡해지고 중첩이 깊어질수록 가독성 저하와 유지보수의 어려움이 뒤따르게 됩니다.
이러한 문제점에 직면했을때, 복잡한 조건문을 더욱 직관적이고 유지보수하기 쉬운 구조로 개선하고 고민했던 과정에 대해 소개시켜드리려고 합니다.
배경
사내에서는 클라우드 자원을 화면에 표현할 때, 여러 내부 시스템의 상태값을 조합하여 최종적으로 UI에 보여줄 상태로 매핑해야 합니다.
하지만 실제로는 각 자원의 내부 상태와 다양한 속성들이 복합적으로 얽혀 있어, 이 상태 매핑 로직이 매우 복잡하게 구성될 수밖에 없었습니다.

각 상태값에 따른 정책 내용의 일부를 재구성한 예시입니다.
초기 개발 단계에서는 단순히 반복되는 규칙을 찾고, if 문으로 그룹화하여 조건을 처리했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
if (status2 === "A_") {
return {
cluster: stateMap.error,
node: stateMap.error,
};
}
if (status1 === "C" || status1 === "D") {
return {
cluster: stateMap.no_defined,
node: stateMap.no_defined,
};
}
if (status1 === "A") {
return {
cluster: stateMap.creating,
node: stateMap.creating,
};
}
if (status1 === "B") {
if (status2 === "H_") {
return {
cluster: stateMap.creating,
node: stateMap.creating,
};
}
if (status2 === "D_") {
return {
cluster: stateMap.error,
node: stateMap.error,
};
}
if (status2 === "F_") {
return {
cluster: stateMap.deleting,
node: stateMap.deleting,
};
}
{ ... }
// 조기리턴을 통해 위 조건에 해당하지 않는 모든 케이스를 일괄 처리
// => 그래서 어떤 케이스들이 있는데? (조건식 분석 필요)
return {
cluster: stateMap.normal,
node: stateMap.normal,
};
}
return {
cluster: stateMap.no_defined,
node: stateMap.no_defined,
};
그런데 위 코드는 아래와 같은 문제점이 있었습니다.
-
중첩된 if문 로직에 의해 코드 가독성이 떨어집니다.
-
중복된 로직 처리가 개발자의 해석에 의존하기 때문에, 코드에 반영된 로직을 직관적으로 이해하기 어려웠습니다.
-
조건이 누락되거나, 예외 케이스(Edge Case)가 발생했을 때 디버깅이 어려웠으며, 중첩된 로직을 일일이 추적해야만 원인을 파악할 수 있었습니다.
-
반복을 감안하고 직관성을 위해 모든 케이스를 정의하는 방법도 있지만 코드가 길어지는 문제가 있습니다.

if문 중첩 내부에서 case4는 위 예시의 else문에 해당합니다. 해당 케이스에 어떤 요소들이 있는지 확인하기 위해서는 상위 if문 블록부터 타고 타고 들어야 확인해야하는 번거로움이 있습니다.
이러한 조건식을 보다 직관적이고 이해하기 쉽게 표현하도록 어떻게 개선할 수 있을까요?
개선 하기
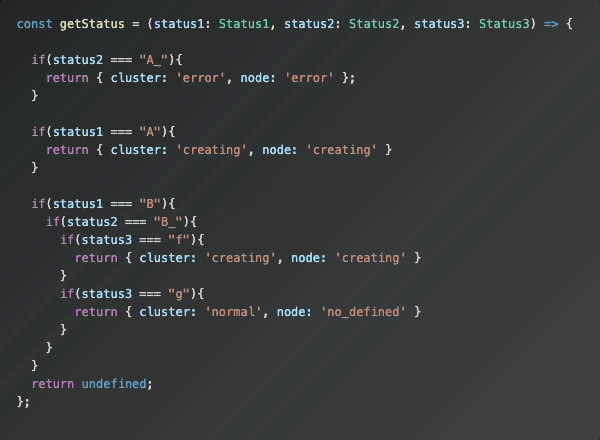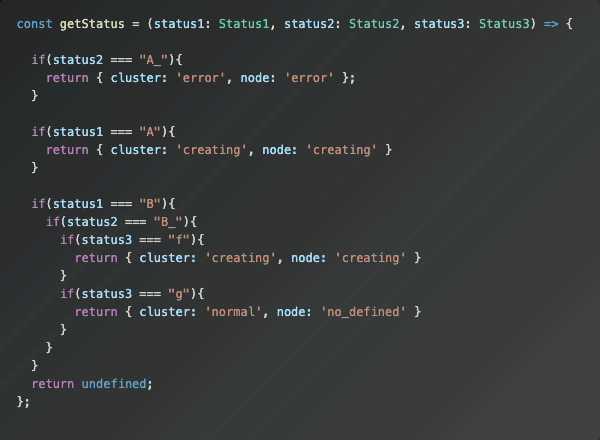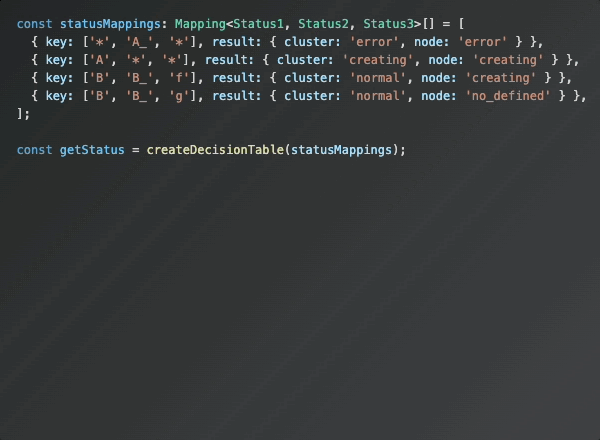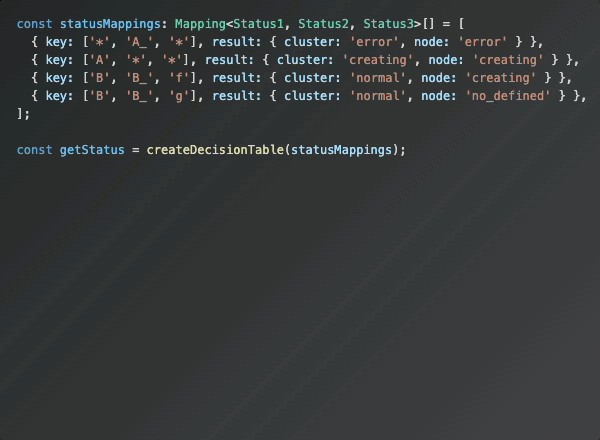
복잡한 조건문 대신, 각 케이스에 대해 정의된 의사 결정 테이블(Decision Table) 형태로 표현한다면 이러한 문제를 해결할 수 있다고 생각했습니다.
의사결정 테이블이란? 다양한 조건 조합에 따른 결과를 표 형태로 명확하게 정의하는 방법입니다.
조건이 많아질수록 복잡해지는 if-else 구조를 간단한 매핑 테이블로 대체할 수 있습니다.
결국 위 로직은 정책 명세서를 기반으로 케이스를 분리하여 처리하고 있습니다.
이러한 정책 역시 테이블 형태로 정의되어있으니, 정책 명세서의 구조에 맞춰 코드에 반영한다면, 각 케이스의 조건과 결과를 보다 직관적으로 확인할 수 있습니다.
1
2
3
4
5
6
7
8
// pseudo code
const decisionTable = [
[["A1", "B1", "C1"], "a"],
[["A2", "B2", "C2"], "b"],
[["A3", "*", "*"], "c"],
];
getResult(decisionTable, A, B, C); // "a"
코드 구현
아이디어는 간단합니다. 사전에 정의한 상태 값에 매칭되는 케이스를 찾아, 그에 맞는 결과 값을 반환합니다.
1
2
3
4
5
6
7
8
const WILD_SYMBOL = "*";
type WithWildcard<T> = T | typeof WILD_SYMBOL;
export type Mapping<I extends readonly unknown[], T> = {
key: { [K in keyof I]: WithWildcard<I[K]> };
result: T | undefined;
};
*는 어떤 값이 와도 매칭될 수 있는 와일드카드입니다. (조건을 신경쓰지 않고 넘어가도록 처리)Mapping은 조건(Key)과 결과(Result)를 정의하는 타입입니다.- 외부에서 다양한 타입을
Generic으로 전달받을 수 있도록 유연하게 처리합니다.
- 외부에서 다양한 타입을
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
export const createDecisionTable = <TKey extends unknown[], TResult>(
mappings: Mapping<TKey, TResult>[]
) => {
return (...inputs: [...TKey]): TResult | undefined => {
// 모든 매핑된 케이스를 순회
outer: for (const mapping of mappings) {
for (let i = 0; i < inputs.length; i++) {
const keyPart = mapping.key[i];
const inputPart = inputs[i];
// 🛑 조건 불일치 시 다음 케이스로 넘어감
if (keyPart !== WILD_SYMBOL && keyPart !== inputPart) continue outer;
}
// 모든 조건이 만족되면 결과 반환
return mapping.result;
}
return undefined;
};
};
- 매핑 정보를 받고, 이를 활용한 결정 로직을 가진 함수를 반환하는 고차함수 형태로 처리합니다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
type InputStatus = [Status1Type, Status2Type, Status3Type];
type ResultStatus = {
cluster: statusType;
node: statusType;
};
const statusMappings: Mapping<InputStatus, ResultStatus>[] = [
{
key: ["*", "A_", "*"],
result: { cluster: "error", node: "error" },
},
{
key: ["A", "*", "*"],
result: { cluster: "creating", node: "creating" },
},
{
key: ["B", "B_", "f"],
result: { cluster: "normal", node: "no_defined" },
},
{
key: ["B", "B_", "g"],
result: { cluster: "normal", node: "error" },
},
{
key: ["B", "B_", "h"],
result: { cluster: "normal", node: "error" },
},
{
key: ["B", "B_", "e"],
result: { cluster: "normal", node: "deleting" },
},
{
key: ["B", "B_", "*"],
result: { cluster: "normal", node: "normal" },
},
{
key: ["B", "C_", "f"],
result: { cluster: "normal", node: "no_defined" },
},
{
key: ["B", "C_", "g"],
result: { cluster: "normal", node: "error" },
},
{
key: ["B", "C_", "h"],
result: { cluster: "normal", node: "error" },
},
{
key: ["B", "C_", "e"],
result: { cluster: "normal", node: "deleting" },
},
{
key: ["B", "C_", "*"],
result: { cluster: "normal", node: "normal" },
},
{ ... }
];
const getStatusResult = createDecisionTable(statusMappings);
const result = getStatusResult(status1, status2, node);
-
createDecisionTable로 생성된getStatusResult는 입력받은 상태 값과 정의된 매핑 정보를 순회하며 매칭 여부를 확인합니다. -
매칭된 결과가 있으면 해당 값을 반환하고, 없으면 undefined를 반환합니다.
성능 개선
현재 로직은 입력받은 상태 값을 기준으로 모든 매핑 정보를 순회하며 매칭 여부를 확인하는 구조입니다. 즉, N개의 케이스가 정의되어 있을 때, 최대 O(N)의 순회가 발생합니다.
이는 케이스의 개수가 많아질수록 탐색 시간이 선형적으로 증가하는 문제를 야기합니다. 따라서 매핑 정보가 많아질수록 성능 저하가 발생할 수 있습니다.
이 문제를 해결하기 위해 계층적 탐색이 가능한 Trie(트라이) 자료구조를 활용했습니다.
Trie
Trie는 문자열이나 키 조합을 효율적으로 관리하기 위한 트리 형태의 자료구조입니다.
예를 들어, 다음과 같은 키 조합이 있다고 가정한다면 Trie로 표현했을때 다음과 같은 구조를 가지게됩니다.
1
2
3
4
["*", "A_", "*"] { cluster: "error", node: "error" }
["A", "*", "*"] { cluster: "creating", node: "creating" }
["B", "B_", "*"] { cluster: "normal", node: "normal" }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
root
├── *
│ └── A_
│ └── *
│ └── ✨ { cluster: "error", node: "error" }
├── A
│ └── *
│ └── *
│ └── ✨ { cluster: "creating", node: "creating" }
└── B
└── B_
└── *
└── ✨ { cluster: "normal", node: "normal" }
즉, 접두사 단위로 트리 노드를 이동하며 모든 매핑을 순회하지 않고 키의 길이에 해당하는 필요한 경로만 우선적으로 탐색하게됩니다.
구현을 위해 먼저, Trie의 기본 단위인 TrieNode와 이를 관리하는 Trie 클래스를 정의합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class TrieNode<TResult> {
children: Map<string, TrieNode<TResult>>;
result: TResult | null;
constructor() {
this.children = new Map();
this.result = null;
}
}
class Trie<TResult> {
root: TrieNode<TResult>;
constructor() {
this.root = new TrieNode<TResult>();
}
// 키 등록
insert(keyParts: string[], result: TResult) {
let currentNode = this.root;
for (const part of keyParts) {
if (!currentNode.children.has(part)) {
currentNode.children.set(part, new TrieNode<TResult>());
}
currentNode = currentNode.children.get(part)!;
}
currentNode.result = result;
}
// 키 탐색
search(keyParts: string[]): TResult | undefined {
return this._searchRecursive(this.root, keyParts, 0);
}
이어서, 와일드카드(*)에 대한 탐색을 지원하기 위해, 재귀적으로 탐색을 진행하며 자식 노드를 방문합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 재귀 탐색 (와일드카드 포함)
private _searchRecursive(
node: TrieNode<TResult>,
keyParts: string[],
index: number
): TResult | undefined {
if (index === keyParts.length) {
return node.result ?? undefined;
}
const part = keyParts[index];
for (const [childKey, childNode] of node.children) {
if (childKey === part || childKey === WILD_SYMBOL) {
const res = this._searchRecursive(childNode, keyParts, index + 1);
if (res !== undefined) return res; // 첫 매칭 결과 즉시 반환
}
}
return undefined;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
const createDecisionTable = <TKey extends string[], TResult>(
mappings: Mapping<TKey, TResult>[]
) => {
const trie = new Trie<TResult>();
// Trie에 모든 매핑을 등록
for (const mapping of mappings) {
trie.insert(mapping.key, mapping.result);
}
// 검색 함수 반환
return (...inputs: [...TKey]): TResult | undefined => {
return trie.search(inputs);
};
};
Trie자료구조를 통해 키의 각 부분(상태값)을 계층적으로 분기하여 저장하고 탐색 시에는 각 상태값에 해당하는 분기만 따라갈 수 있도록 개선되었습니다.
즉 O(N)이 아니라 O(K) (K=키의 길이, 즉 상태값의 개수)로 탐색 성능을 향상시킬 수 있었습니다.
처음 구조를 생성할때에는 O(N * K)의 시간복잡도를 가지지만, 테이블은 처음 생성 후 조건문에서 반복문으로 사용하므로 탐색이 반복되는 위 구조에서는 유리한 형태를 가질 수 있습니다.
결론
결과적으로 복잡한 if 문을 객체 기반 매핑 테이블로 재구성함으로써, 각 케이스를 더욱 빠르고 직관적으로 조회할 수 있는 구조로 개선할 수 있었습니다.
물론, if 문이나 switch 문에서도 모든 케이스를 정의한다는 관점으로 접근했을때 동일하게 처리할 수 있지만, 코드가 길어지고 복잡해져 가독성이 떨어진다는 단점이 있습니다.
반면, 객체 매핑 방식은 상태와 결과를 명확하게 정의하기 때문에, 개발 중 매핑 정보가 변경되더라도 해당 상태값이 어떤 결과를 반환할지 쉽게 파악할 수 있습니다.
덕분에 디버깅 시간도 단축되었으며, 케이스 분기가 많아질수록 그 유용성이 더욱 두드러지는 구조라고 생각합니다.😄
댓글남기기